그라파나 Grafana
소개 및 웹 접속 : TSDB 데이터를 시각화, 다양한 데이터 형식 지원(메트릭, 로그, 트레이스 등) - 링크 9.5 Docs
About Grafana | Grafana documentation
Thank you! Your message has been received!
grafana.com
- Grafana open source software enables you to query, visualize, alert on, and explore your metrics, logs, and traces wherever they are stored.
- Grafana OSS provides you with tools to turn your time-series database (TSDB) data into insightful graphs and visualizations.
- 그라파나는 시각화 솔루션으로 데이터 자체를 저장하지 않음 → 현재 실습 환경에서는 데이터 소스는 프로메테우스를 사용
- 접속 정보 확인 및 로그인 : 기본 계정 - admin / prom-operator
# 그라파나 버전 확인
kubectl exec -it -n monitoring deploy/kube-prometheus-stack-grafana -- grafana-cli --version
grafana cli version 10.4.0
# ingress 확인
kubectl get ingress -n monitoring kube-prometheus-stack-grafana
kubectl describe ingress -n monitoring kube-prometheus-stack-grafana
# ingress 도메인으로 웹 접속 : 기본 계정 - admin / prom-operator
echo -e "Grafana Web URL = https://grafana.$MyDomain"
# 서비스 주소 확인
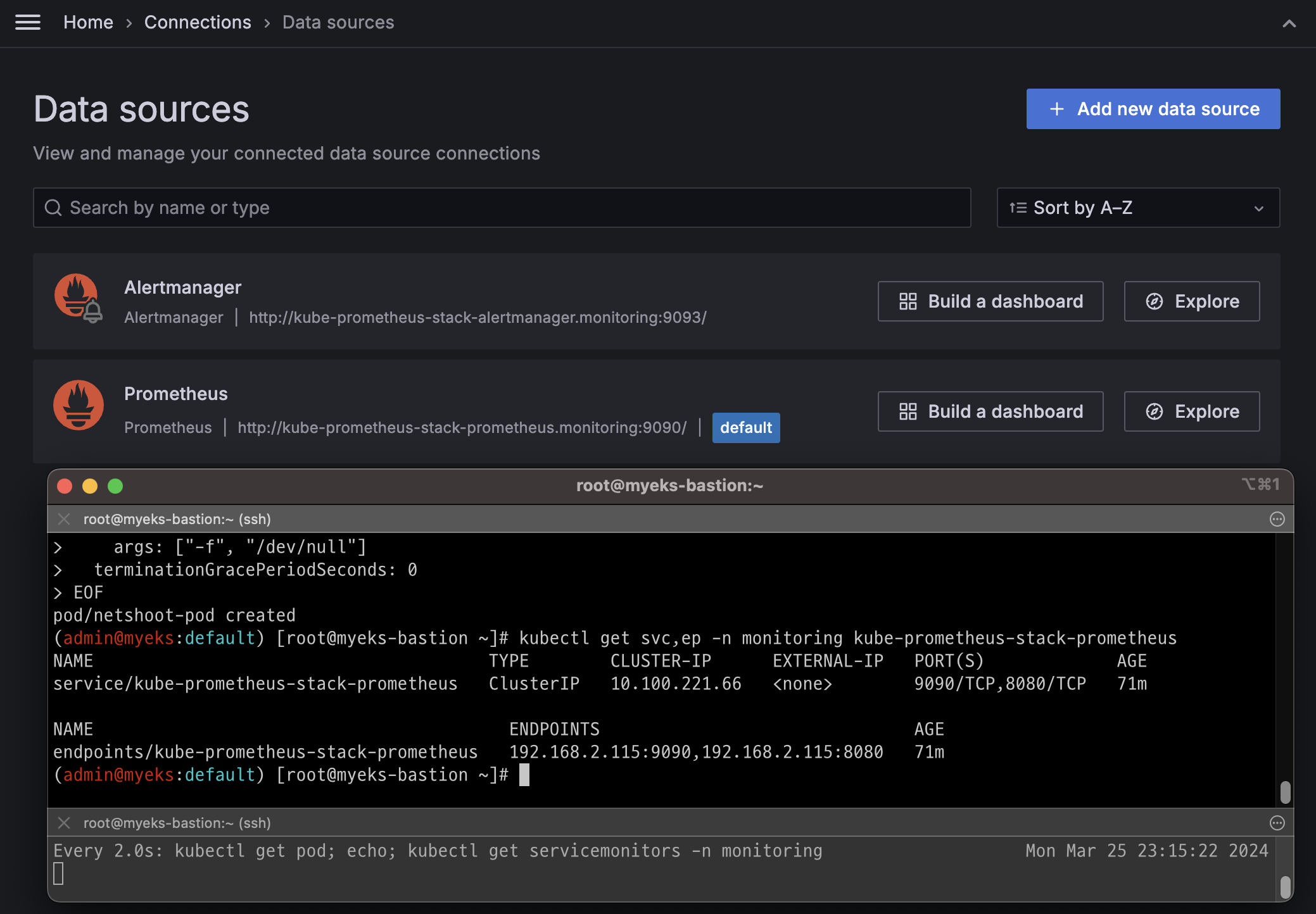
kubectl get svc,ep -n monitoring kube-prometheus-stack-prometheus
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/kube-prometheus-stack-prometheus ClusterIP 10.100.143.5 <none> 9090/TCP 21m
NAME ENDPOINTS AGE
endpoints/kube-prometheus-stack-prometheus 192.168.2.93:9090 21m
확인

대시보드 사용 : 기본 대시보드와 공식 대시보드 가져오기
- 스택을 통해서 설치된 기본 대시보드 확인 : Dashboards → Browse
- (대략) 분류 : 자원 사용량 - Cluster/POD Resources, 노드 자원 사용량 - Node Exporter, 주요 애플리케이션 - CoreDNS 등
- 확인해보자 - K8S / CR / Cluster, Node Exporter / Use Method / Cluster
- Kubernetes / Views / Global] Dashboard → New → Import → 15757 력입력 후 Load ⇒ 데이터소스(Prometheus 선택) 후 Import 클릭
- [1 Kubernetes All-in-one Cluster Monitoring KR] Dashboard → New → Import → 17900 입력 후 Load ⇒ 데이터소스(Prometheus 선택) 후 Import 클릭

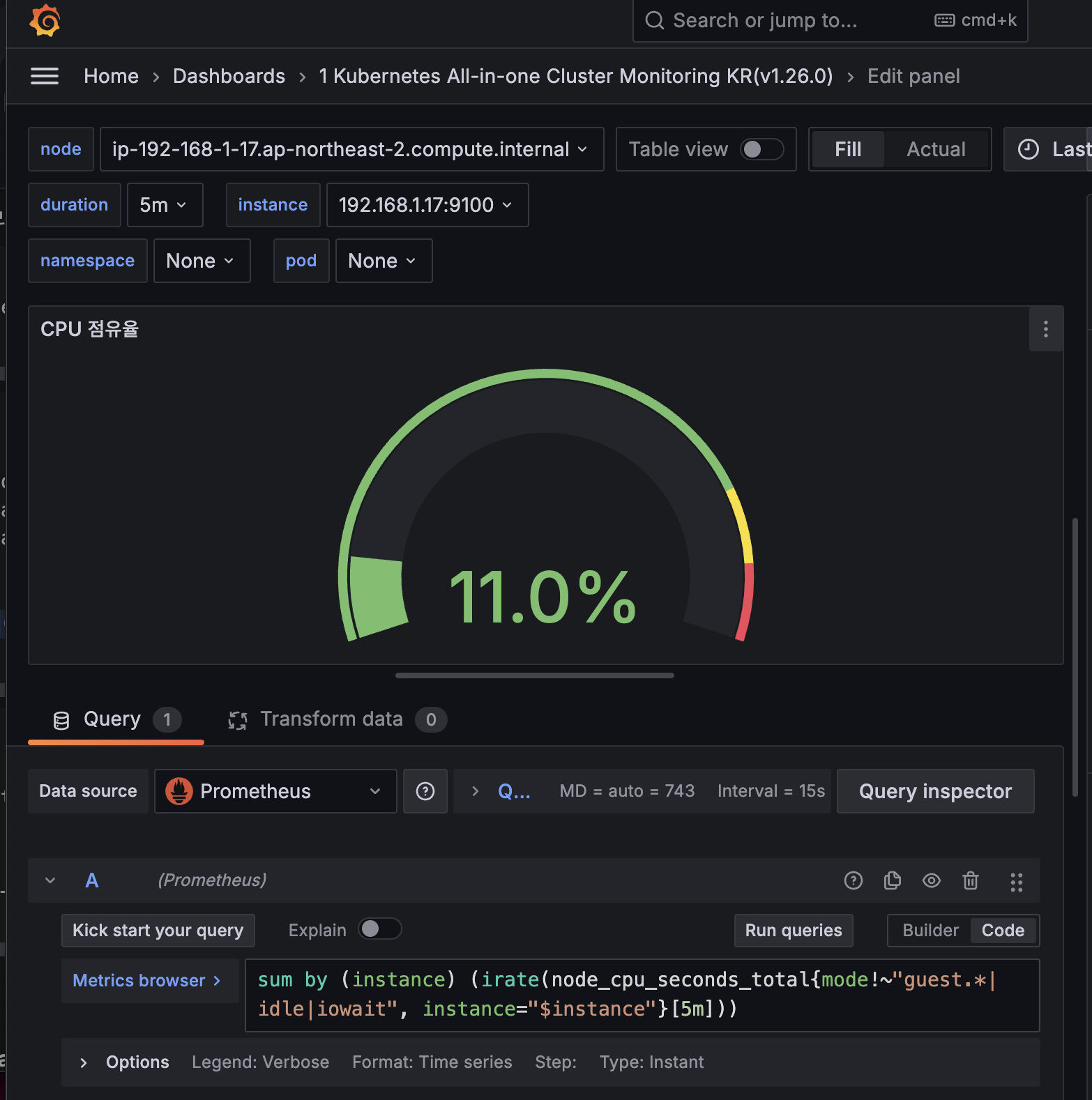
해당 패널에서 Edit → 아래 수정 쿼리 입력 후 Run queries 클릭 → 상단 Save 후 Apply
sum by (node) (irate(node_cpu_seconds_total{mode!~"guest.*|idle|iowait", node="$node"}[5m]))
node_cpu_seconds_total
node_cpu_seconds_total{mode!~"guest.*|idle|iowait"}
avg(node_cpu_seconds_total{mode!~"guest.*|idle|iowait"}) by (node)
avg(node_cpu_seconds_total{mode!~"guest.*|idle|iowait"}) by (instance)
# 수정
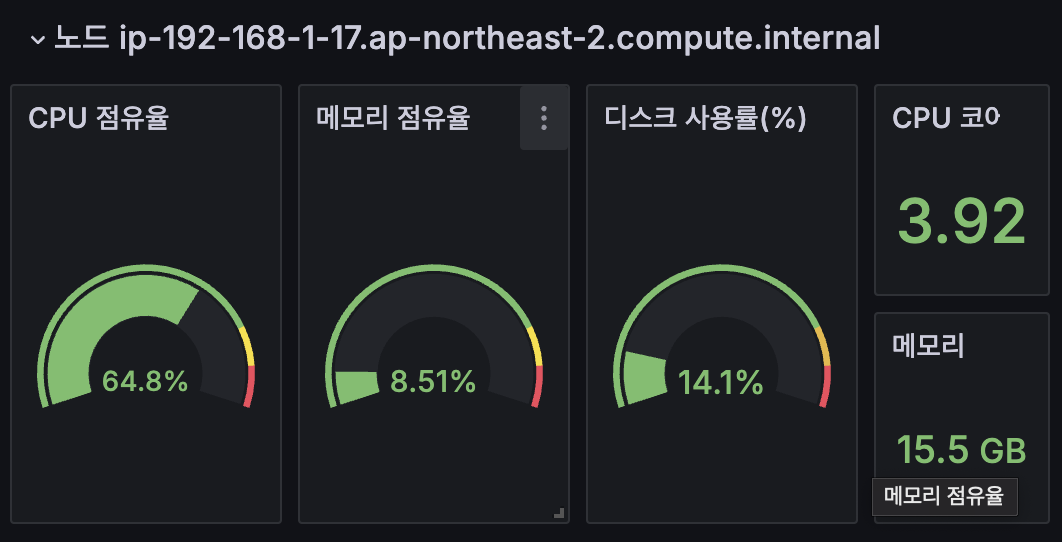
sum by (instance) (irate(node_cpu_seconds_total{mode!~"guest.*|idle|iowait", instance="$instance"}[5m]))
# 수정 : 메모리 점유율
(node_memory_MemTotal_bytes{instance="$instance"}-node_memory_MemAvailable_bytes{instance="$instance"})/node_memory_MemTotal_bytes{instance="$instance"}
# 수정 : 디스크 사용률
sum(node_filesystem_size_bytes{instance="$instance"} - node_filesystem_avail_bytes{instance="$instance"}) by (node) / sum(node_filesystem_size_bytes{instance="$instance"}) by (node)
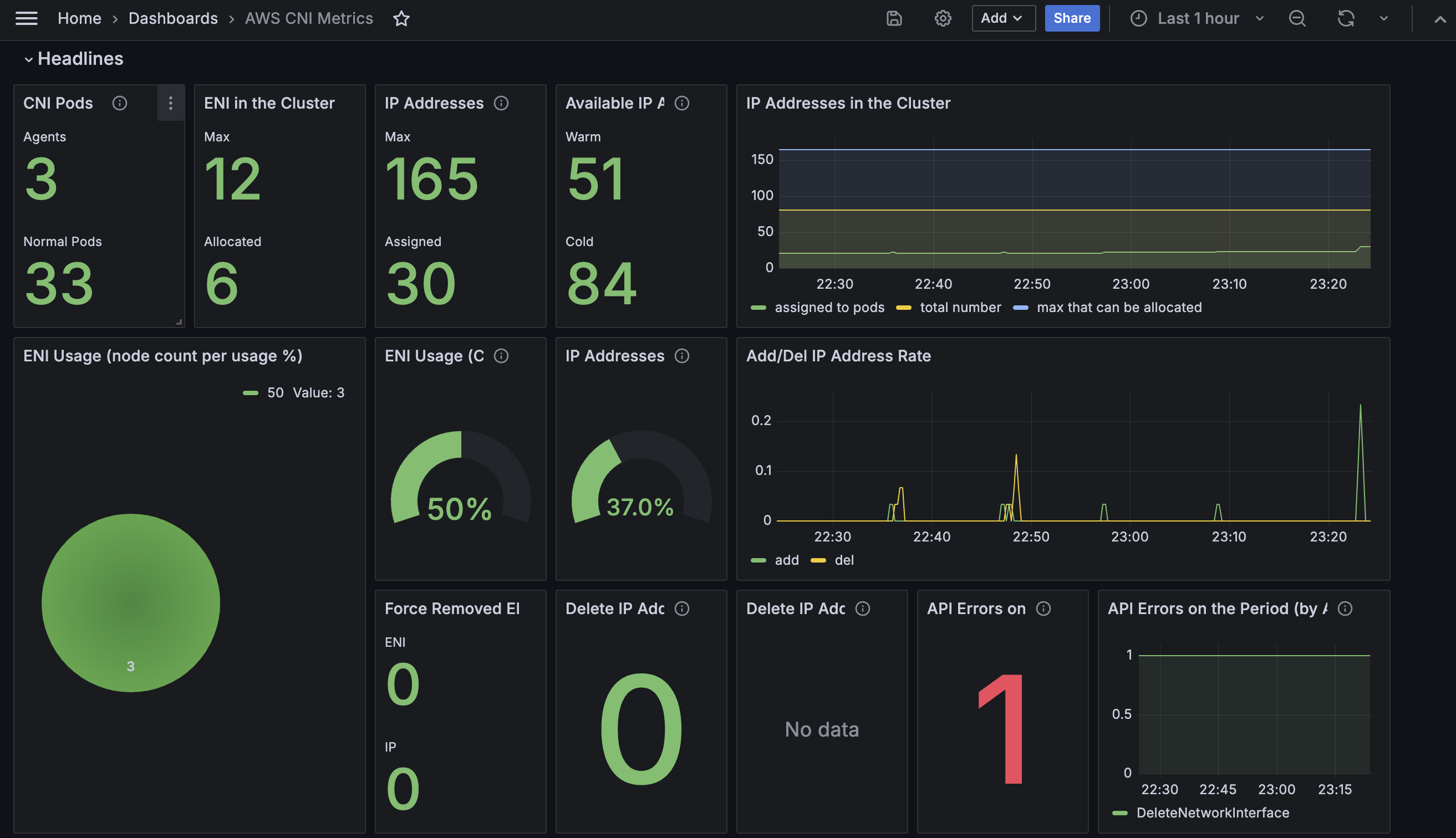
[Amazon EKS] AWS CNI Metrics 16032 - 링크
# PodMonitor 배포
cat <<EOF | kubectl create -f -
apiVersion: monitoring.coreos.com/v1
kind: PodMonitor
metadata:
name: aws-cni-metrics
namespace: kube-system
spec:
jobLabel: k8s-app
namespaceSelector:
matchNames:
- kube-system
podMetricsEndpoints:
- interval: 30s
path: /metrics
port: metrics
selector:
matchLabels:
k8s-app: aws-node
EOF
# PodMonitor 확인
kubectl get podmonitor -n kube-system
NGINX 애플리케이션 모니터링 대시보드 추가
그라파나에 12708 대시보드 추가
# scale out
kubectl scale deployment nginx --replicas 9pod확인

[중급] Panel 패널 - Link
Panels and visualizations | Grafana documentation
Thank you! Your message has been received!
grafana.com
실습 준비 : 신규 대시보스 생성 → 패널 생성(Code 로 변경) → 쿼리 입력 후 Run queries 클릭 후 오른쪽 상단 Apply 클릭 → 대시보드 상단 저장
1. Time series : 아래 쿼리 입력 후 오른쪽 입력 → Title(노드별 5분간 CPU 사용 변화율)
node_cpu_seconds_total
rate(node_cpu_seconds_total[5m])
sum(rate(node_cpu_seconds_total[5m]))
sum(rate(node_cpu_seconds_total[5m])) by (instance)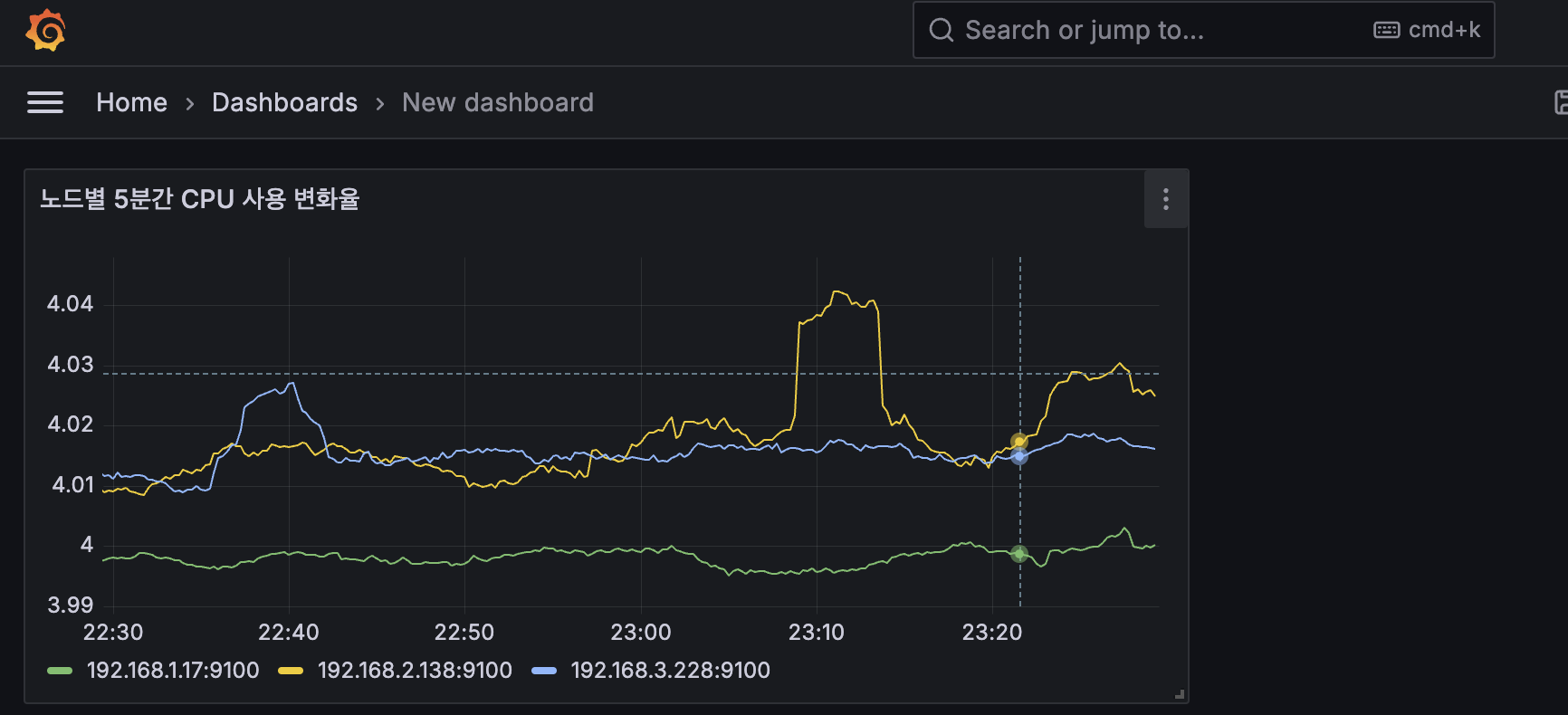
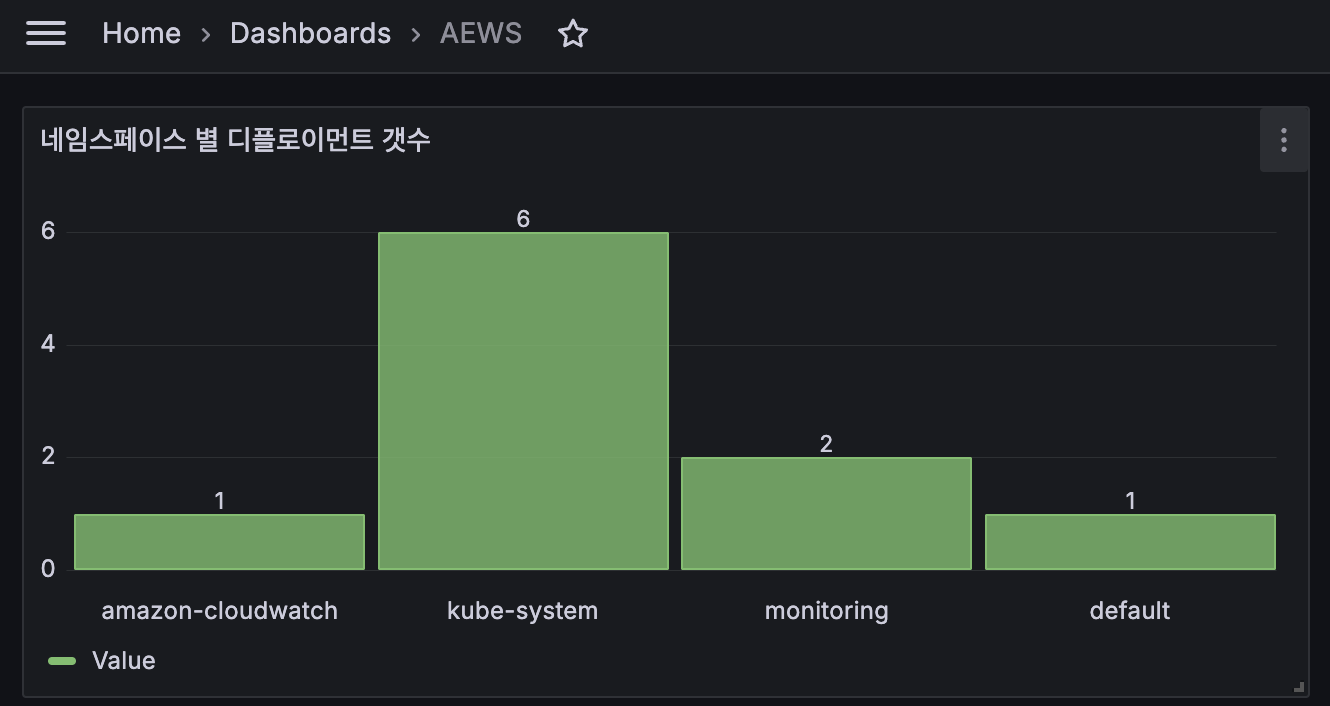
2.Bar chart : Add → Visualization 오른쪽(Bar chart) ⇒ 쿼리 Options : Format(Table), Type(Instance) → Title(네임스페이스 별 디플로이먼트 갯수)
kube_deployment_status_replicas_available
count(kube_deployment_status_replicas_available) by (namespace)
3. Stat : Add → Visualization 오른쪽(Stat) → Title(nginx 파드 수)
kube_deployment_spec_replicas
kube_deployment_spec_replicas{deployment="nginx"}
# scale out
kubectl scale deployment nginx --replicas 6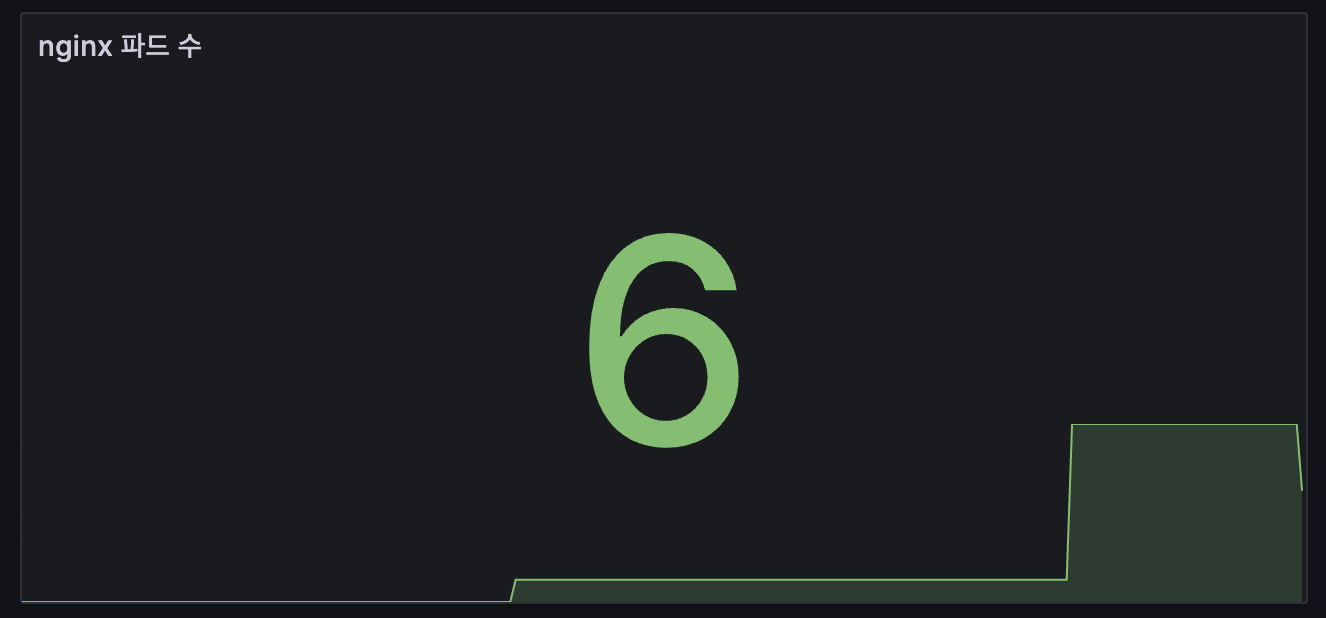
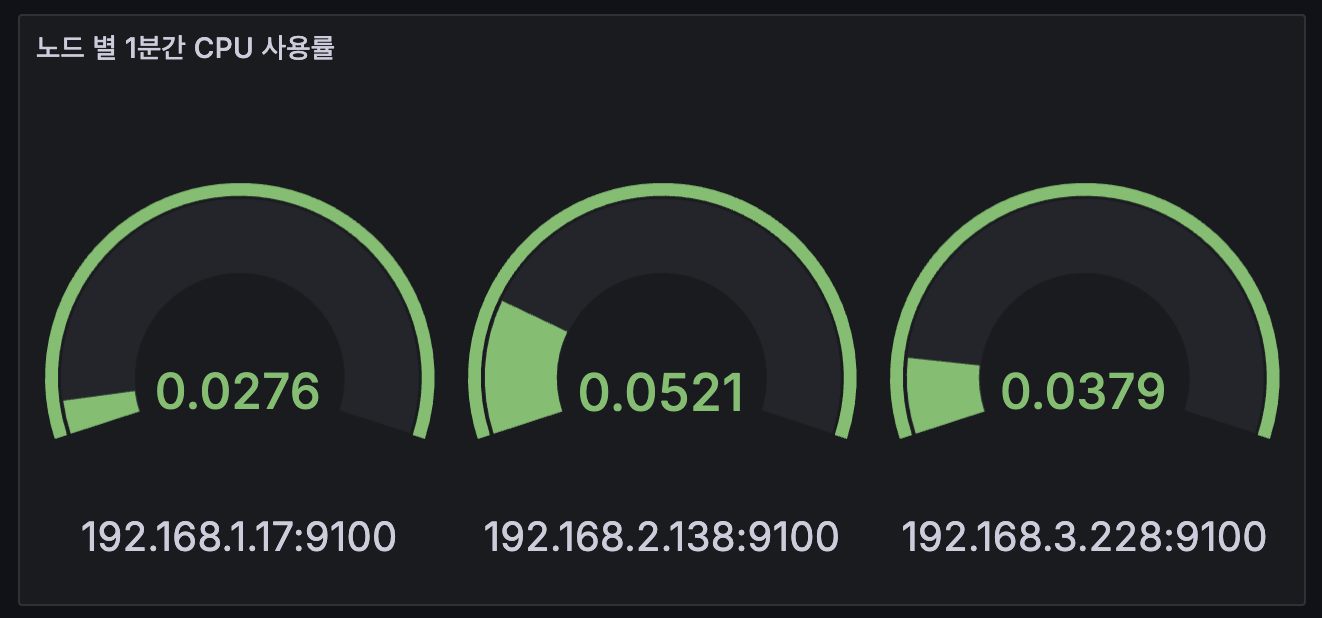
4. Gauge : Add → Visualization 오른쪽(Gauge) → Title(노드 별 1분간 CPU 사용률)
node_cpu_seconds_total{mode!~"guest.*|idle|iowait"}[1m]
node_cpu_seconds_total
node_cpu_seconds_total{mode="idle"}
node_cpu_seconds_total{mode="idle"}[1m]
rate(node_cpu_seconds_total{mode="idle"}[1m])
avg(rate(node_cpu_seconds_total{mode="idle"}[1m])) by (instance)
1 - (avg(rate(node_cpu_seconds_total{mode="idle"}[1m])) by (instance))
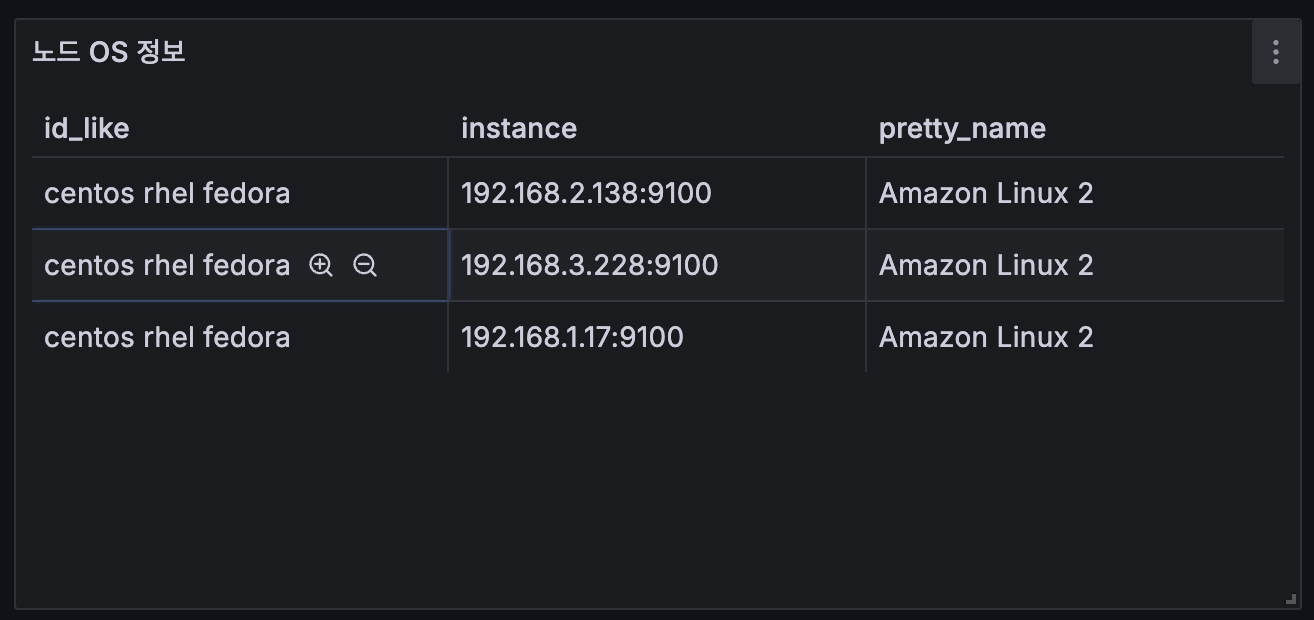
5. Table : Add → Visualization 오른쪽(Table) ⇒ 쿼리 Options : Format(Table), Type(Instance) → Title(노드 OS 정보)
node_os_infoTransform data → Organize fields by name : id_like, instance, name, pretty_name
그라파나 얼럿 Alert
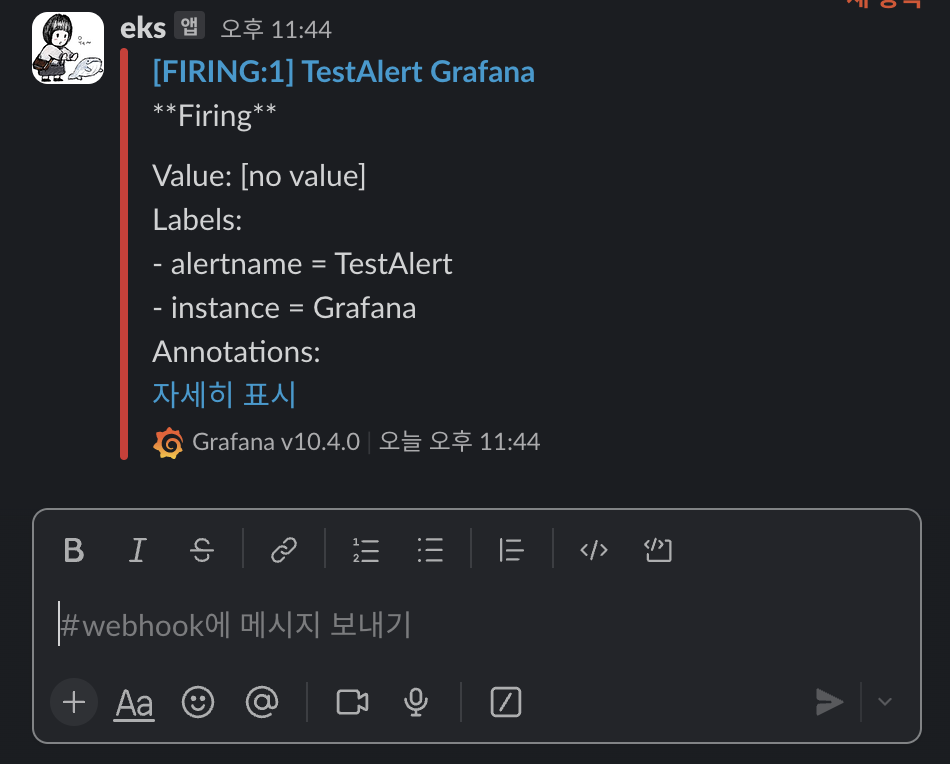
1. 그라파나 → Alerting → Alert ruels → Create alert rule : nginx 웹 요청 1분 동안 누적 60 이상 시 Alert 설정
2. Contact points → Add contact point 클릭
- Integration : 슬랙
- Webhook URL : ####
- Optional Slack settings → Username : 메시지 구분을 위해서 각자 자신의 닉네임 입력
- 오른쪽 상단 : Test 해보고 저장
3. Notification policies : 기본 정책 수정 Edit - Default contact point(slack)
4.nginx 반복 접속 실행 후 슬랙 채널 알람 확인
while true; do curl -s https://nginx.$MyDomain -I | head -n 1; date; done메트릭 이미지 포함 알람 : 그라파나 이미지를 포함한 슬랙 얼럿 설정 - 링크 & Grafana - Image Render Plugin & Slack Alert 연동 - 링크
이것으로 4주차 스터디 공유를 마치겠습니다!
'study > AEWS 2기' 카테고리의 다른 글
| AEWS 2기 5주차 두번째 (4) | 2024.04.05 |
|---|---|
| AEWS 2기 5주차 첫번째 (1) | 2024.04.05 |
| AEWS 2기 4주차 두번째 (1) | 2024.03.30 |
| AEWS 2기 4주차 첫번째 (0) | 2024.03.25 |
| AEWS 2기 3주차 (0) | 2024.03.22 |



