5주차 스터디 공유 시작하겠습니다.
1. HPA - Horizontal Pod Autoscaler
실습 : kube-ops-view 와 그라파나(17125)에서 모니터링 같이 해보자 - 링크 Docs k8s
Horizontal Pod Autoscaling
In Kubernetes, a HorizontalPodAutoscaler automatically updates a workload resource (such as a Deployment or StatefulSet), with the aim of automatically scaling the workload to match demand. Horizontal scaling means that the response to increased load is to
kubernetes.io
17125_rev1.json : 대시보드 → Import : JSON 내용 복붙!
{
"__inputs": [],
"__requires": [
{
"type": "grafana",
"id": "grafana",
"name": "Grafana",
"version": "6.1.6"
},
{
"type": "panel",
"id": "graph",
"name": "Graph",
"version": ""
},
{
"type": "datasource",
"id": "prometheus",
"name": "Prometheus",
"version": "1.0.0"
},
{
"type": "panel",
"id": "singlestat",
"name": "Singlestat",
"version": ""
}
],
"annotations": {
"list": [
{
"builtIn": 1,
"datasource": "-- Grafana --",
"enable": true,
"hide": true,
"iconColor": "rgba(0, 211, 255, 1)",
"name": "Annotations & Alerts",
"type": "dashboard"
}
]
},
"editable": true,
"gnetId": 17125,
"graphTooltip": 0,
"id": null,
"iteration": 1558717029334,
"links": [],
"panels": [
{
"cacheTimeout": null,
"colorBackground": false,
"colorValue": false,
"colors": [
"#299c46",
"rgba(237, 129, 40, 0.89)",
"#d44a3a"
],
"datasource": "$datasource",
"format": "none",
"gauge": {
"maxValue": 100,
"minValue": 0,
"show": false,
"thresholdLabels": false,
"thresholdMarkers": true
},
"id": 5,
"interval": null,
"links": [],
"mappingType": 1,
"mappingTypes": [
{
"name": "value to text",
"value": 1
},
{
"name": "range to text",
"value": 2
}
],
"maxDataPoints": 100,
"nullPointMode": "connected",
"nullText": null,
"postfix": "",
"postfixFontSize": "50%",
"prefix": "",
"prefixFontSize": "50%",
"rangeMaps": [
{
"from": "null",
"text": "N/A",
"to": "null"
}
],
"sparkline": {
"fillColor": "rgba(31, 118, 189, 0.18)",
"full": false,
"lineColor": "rgb(31, 120, 193)",
"show": true
},
"tableColumn": "",
"targets": [
{
"expr": "kube_horizontalpodautoscaler_status_desired_replicas{job=\"kube-state-metrics\", namespace=\"$namespace\"}",
"format": "time_series",
"intervalFactor": 2,
"legendFormat": "",
"refId": "A"
}
],
"thresholds": "",
"title": "Desired Replicas",
"type": "singlestat",
"valueFontSize": "80%",
"valueMaps": [
{
"op": "=",
"text": "0",
"value": "null"
}
],
"valueName": "current"
},
{
"cacheTimeout": null,
"colorBackground": false,
"colorValue": false,
"colors": [
"#299c46",
"rgba(237, 129, 40, 0.89)",
"#d44a3a"
],
"datasource": "$datasource",
"format": "none",
"gauge": {
"maxValue": 100,
"minValue": 0,
"show": false,
"thresholdLabels": false,
"thresholdMarkers": true
},
"gridPos": {
"h": 3,
"w": 6,
"x": 6,
"y": 0
},
"id": 6,
"interval": null,
"links": [],
"mappingType": 1,
"mappingTypes": [
{
"name": "value to text",
"value": 1
},
{
"name": "range to text",
"value": 2
}
],
"maxDataPoints": 100,
"nullPointMode": "connected",
"nullText": null,
"postfix": "",
"postfixFontSize": "50%",
"prefix": "",
"prefixFontSize": "50%",
"rangeMaps": [
{
"from": "null",
"text": "N/A",
"to": "null"
}
],
"sparkline": {
"fillColor": "rgba(31, 118, 189, 0.18)",
"full": false,
"lineColor": "rgb(31, 120, 193)",
"show": true
},
"tableColumn": "",
"targets": [
{
"expr": "kube_horizontalpodautoscaler_status_current_replicas{job=\"kube-state-metrics\", namespace=\"$namespace\"}",
"format": "time_series",
"intervalFactor": 2,
"legendFormat": "",
"refId": "A"
}
],
"thresholds": "",
"title": "Current Replicas",
"type": "singlestat",
"valueFontSize": "80%",
"valueMaps": [
{
"op": "=",
"text": "0",
"value": "null"
}
],
"valueName": "current"
},
{
"cacheTimeout": null,
"colorBackground": false,
"colorValue": false,
"colors": [
"#299c46",
"rgba(237, 129, 40, 0.89)",
"#d44a3a"
],
"datasource": "$datasource",
"format": "none",
"gauge": {
"maxValue": 100,
"minValue": 0,
"show": false,
"thresholdLabels": false,
"thresholdMarkers": true
},
"gridPos": {
"h": 3,
"w": 6,
"x": 12,
"y": 0
},
"id": 7,
"interval": null,
"links": [],
"mappingType": 1,
"mappingTypes": [
{
"name": "value to text",
"value": 1
},
{
"name": "range to text",
"value": 2
}
],
"maxDataPoints": 100,
"nullPointMode": "connected",
"nullText": null,
"postfix": "",
"postfixFontSize": "50%",
"prefix": "",
"prefixFontSize": "50%",
"rangeMaps": [
{
"from": "null",
"text": "N/A",
"to": "null"
}
],
"sparkline": {
"fillColor": "rgba(31, 118, 189, 0.18)",
"full": false,
"lineColor": "rgb(31, 120, 193)",
"show": false
},
"tableColumn": "",
"targets": [
{
"expr": "kube_horizontalpodautoscaler_spec_min_replicas{job=\"kube-state-metrics\", namespace=\"$namespace\"}",
"format": "time_series",
"intervalFactor": 2,
"legendFormat": "",
"refId": "A"
}
],
"thresholds": "",
"title": "Min Replicas",
"type": "singlestat",
"valueFontSize": "80%",
"valueMaps": [
{
"op": "=",
"text": "0",
"value": "null"
}
],
"valueName": "current"
},
{
"cacheTimeout": null,
"colorBackground": false,
"colorValue": false,
"colors": [
"#299c46",
"rgba(237, 129, 40, 0.89)",
"#d44a3a"
],
"datasource": "$datasource",
"format": "none",
"gauge": {
"maxValue": 100,
"minValue": 0,
"show": false,
"thresholdLabels": false,
"thresholdMarkers": true
},
"gridPos": {
"h": 3,
"w": 6,
"x": 18,
"y": 0
},
"id": 8,
"interval": null,
"links": [],
"mappingType": 1,
"mappingTypes": [
{
"name": "value to text",
"value": 1
},
{
"name": "range to text",
"value": 2
}
],
"maxDataPoints": 100,
"nullPointMode": "connected",
"nullText": null,
"postfix": "",
"postfixFontSize": "50%",
"prefix": "",
"prefixFontSize": "50%",
"rangeMaps": [
{
"from": "null",
"text": "N/A",
"to": "null"
}
],
"sparkline": {
"fillColor": "rgba(31, 118, 189, 0.18)",
"full": false,
"lineColor": "rgb(31, 120, 193)",
"show": false
},
"tableColumn": "",
"targets": [
{
"expr": "kube_horizontalpodautoscaler_spec_max_replicas{job=\"kube-state-metrics\"}",
"format": "time_series",
"intervalFactor": 2,
"legendFormat": "",
"refId": "A"
}
],
"thresholds": "",
"title": "Max Replicas",
"type": "singlestat",
"valueFontSize": "80%",
"valueMaps": [
{
"op": "=",
"text": "0",
"value": "null"
}
],
"valueName": "current"
},
{
"aliasColors": {},
"bars": false,
"dashLength": 10,
"dashes": false,
"datasource": "$datasource",
"fill": 0,
"gridPos": {
"h": 12,
"w": 24,
"x": 0,
"y": 3
},
"id": 9,
"legend": {
"alignAsTable": false,
"avg": false,
"current": false,
"max": false,
"min": false,
"rightSide": false,
"show": true,
"total": false,
"values": false
},
"lines": true,
"linewidth": 1,
"links": [],
"nullPointMode": "null",
"paceLength": 10,
"percentage": false,
"pointradius": 5,
"points": false,
"renderer": "flot",
"repeat": null,
"seriesOverrides": [
{
"alias": "Max",
"color": "#C4162A"
},
{
"alias": "Min",
"color": "#1F60C4"
}
],
"spaceLength": 10,
"stack": false,
"steppedLine": false,
"targets": [
{
"expr": "kube_horizontalpodautoscaler_status_desired_replicas{job=\"kube-state-metrics\",namespace=\"$namespace\"}",
"format": "time_series",
"intervalFactor": 2,
"legendFormat": "Desired",
"refId": "B"
},
{
"expr": "kube_horizontalpodautoscaler_status_current_replicas{job=\"kube-state-metrics\",namespace=\"$namespace\"}",
"format": "time_series",
"intervalFactor": 2,
"legendFormat": "Running",
"refId": "C"
},
{
"expr": "kube_horizontalpodautoscaler_spec_max_replicas{job=\"kube-state-metrics\",namespace=\"$namespace\"}",
"format": "time_series",
"instant": false,
"intervalFactor": 2,
"legendFormat": "Max",
"refId": "A"
},
{
"expr": "kube_horizontalpodautoscaler_spec_min_replicas{job=\"kube-state-metrics\",namespace=\"$namespace\"}",
"format": "time_series",
"instant": false,
"intervalFactor": 2,
"legendFormat": "Min",
"refId": "D"
}
],
"thresholds": [],
"timeFrom": null,
"timeRegions": [],
"timeShift": null,
"title": "Replicas",
"tooltip": {
"shared": true,
"sort": 0,
"value_type": "individual"
},
"type": "graph",
"xaxis": {
"buckets": null,
"mode": "time",
"name": null,
"show": true,
"values": []
},
"yaxes": [
{
"format": "short",
"label": null,
"logBase": 1,
"max": null,
"min": null,
"show": true
},
{
"format": "short",
"label": null,
"logBase": 1,
"max": null,
"min": null,
"show": true
}
],
"yaxis": {
"align": false,
"alignLevel": null
}
}
],
"refresh": "10s",
"schemaVersion": 18,
"style": "dark",
"tags": [],
"templating": {
"list": [
{
"current": {
"text": "Prometheus",
"value": "Prometheus"
},
"hide": 0,
"includeAll": false,
"label": null,
"multi": false,
"name": "datasource",
"options": [],
"query": "prometheus",
"refresh": 1,
"regex": "",
"skipUrlSync": false,
"type": "datasource"
},
{
"allValue": null,
"current": {},
"datasource": "$datasource",
"definition": "label_values(kube_horizontalpodautoscaler_metadata_generation{job=\"kube-state-metrics\"}, namespace)",
"hide": 0,
"includeAll": false,
"label": "Namespace",
"multi": false,
"name": "namespace",
"options": [],
"query": "label_values(kube_horizontalpodautoscaler_metadata_generation{job=\"kube-state-metrics\"}, namespace)",
"refresh": 2,
"regex": "",
"skipUrlSync": false,
"sort": 0,
"tagValuesQuery": "",
"tags": [],
"tagsQuery": "",
"type": "query",
"useTags": false
},
{
"allValue": null,
"current": {},
"datasource": "$datasource",
"definition": "label_values(kube_horizontalpodautoscaler_labels{job=\"kube-state-metrics\", namespace=\"$namespace\"}, horizontalpodautoscaler)",
"hide": 0,
"includeAll": false,
"label": "Name",
"multi": false,
"name": "horizontalpodautoscaler",
"options": [],
"query": "label_values(kube_horizontalpodautoscaler_labels{job=\"kube-state-metrics\", namespace=\"$namespace\"}, horizontalpodautoscaler)",
"refresh": 2,
"regex": "",
"skipUrlSync": false,
"sort": 0,
"tagValuesQuery": "",
"tags": [],
"tagsQuery": "",
"type": "query",
"useTags": false
}
]
},
"time": {
"from": "now-1h",
"to": "now"
},
"timepicker": {
"refresh_intervals": [
"5s",
"10s",
"30s",
"1m",
"5m",
"15m",
"30m",
"1h",
"2h",
"1d"
],
"time_options": [
"5m",
"15m",
"1h",
"6h",
"12h",
"24h",
"2d",
"7d",
"30d"
]
},
"timezone": "",
"title": "Kubernetes / Horizontal Pod Autoscaler",
"uid": "alJY6yWZz",
"version": 10,
"description": "A quick and simple dashboard for viewing how your horizontal pod autoscaler is doing."
}
php-apache.yaml
# Run and expose php-apache server
curl -s -O https://raw.githubusercontent.com/kubernetes/website/main/content/en/examples/application/php-apache.yaml
cat php-apache.yaml | yh
kubectl apply -f php-apache.yaml
# 확인
kubectl exec -it deploy/php-apache -- cat /var/www/html/index.php
...
# 모니터링 : 터미널2개 사용
watch -d 'kubectl get hpa,pod;echo;kubectl top pod;echo;kubectl top node'
kubectl exec -it deploy/php-apache -- top
# 접속
PODIP=$(kubectl get pod -l run=php-apache -o jsonpath={.items[0].status.podIP})
curl -s $PODIP; echo
파드정보 확인

HPA 생성 및 부하 발생 후 오토 스케일링 테스트 : 증가 시 기본 대기 시간(30초), 감소 시 기본 대기 시간(5분) → 조정 가능
# Create the HorizontalPodAutoscaler : requests.cpu=200m - 알고리즘
# Since each pod requests 200 milli-cores by kubectl run, this means an average CPU usage of 100 milli-cores.
kubectl autoscale deployment php-apache --cpu-percent=50 --min=1 --max=10
kubectl describe hpa
...
Metrics: ( current / target )
resource cpu on pods (as a percentage of request): 0% (1m) / 50%
Min replicas: 1
Max replicas: 10
Deployment pods: 1 current / 1 desired
...
# HPA 설정 확인
kubectl get hpa php-apache -o yaml | kubectl neat | yh
spec:
minReplicas: 1 # [4] 또는 최소 1개까지 줄어들 수도 있습니다
maxReplicas: 10 # [3] 포드를 최대 5개까지 늘립니다
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: php-apache # [1] php-apache 의 자원 사용량에서
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 50 # [2] CPU 활용률이 50% 이상인 경우
# 반복 접속 1 (파드1 IP로 접속) >> 증가 확인 후 중지
while true;do curl -s $PODIP; sleep 0.5; done
# 반복 접속 2 (서비스명 도메인으로 접속) >> 증가 확인(몇개까지 증가되는가? 그 이유는?) 후 중지 >> 중지 5분 후 파드 갯수 감소 확인
# Run this in a separate terminal
# so that the load generation continues and you can carry on with the rest of the steps
kubectl run -i --tty load-generator --rm --image=busybox:1.28 --restart=Never -- /bin/sh -c "while sleep 0.01; do wget -q -O- http://php-apache; done"
파드가 늘어난 것을 볼 수 있다.

빠른 확인
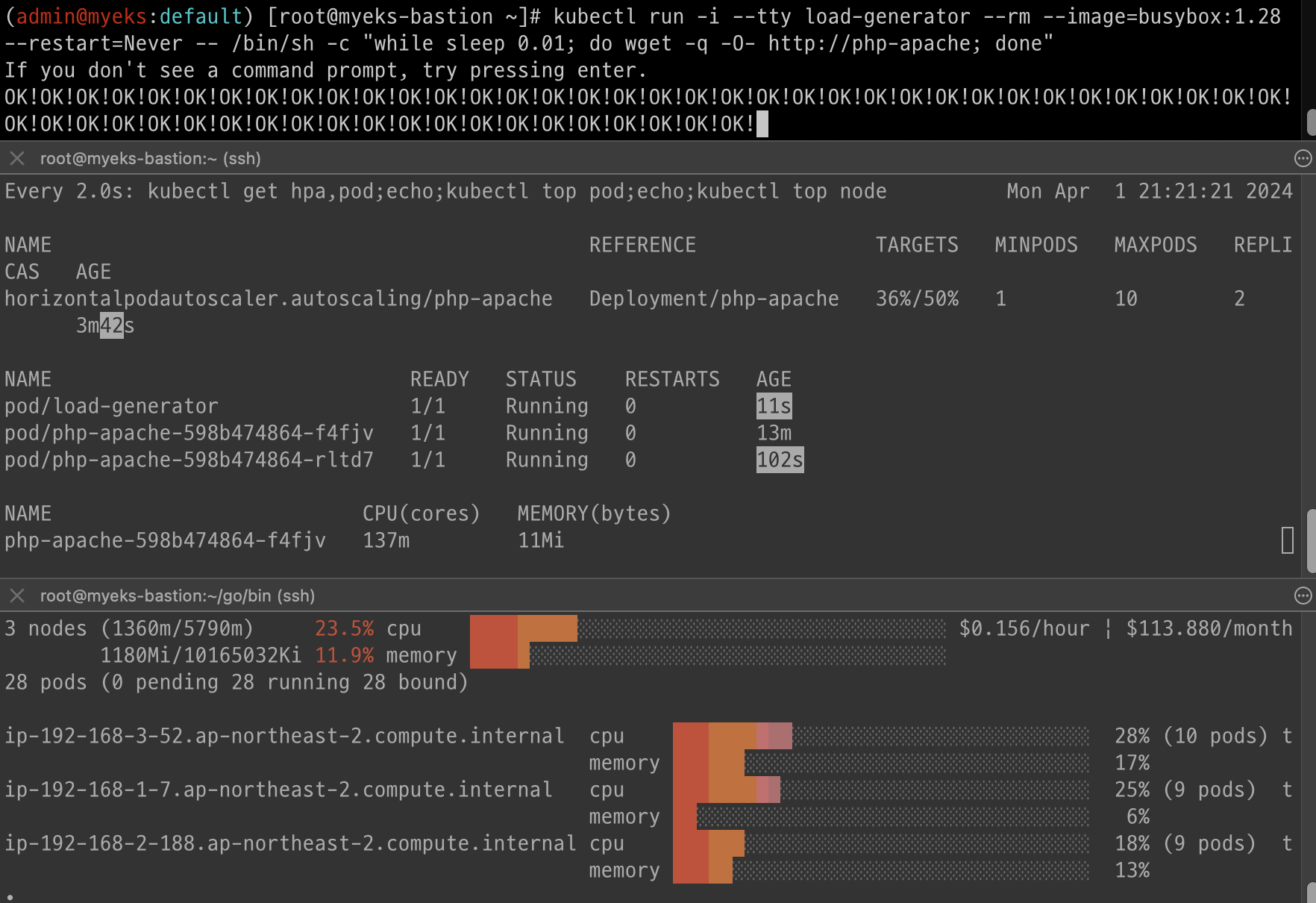
그라파나 확인

-오브젝트 삭제: kubectl delete deploy,svc,hpa,pod --all
2. KEDA - Kubernetes based Event Driven Autoscaler
- KEDA AutoScaler 소개 - Docs DevOcean반면에 KEDA는 특정 이벤트를 기반으로 스케일 여부를 결정할 수 있습니다.이러한 이벤트를 활용하여 worker의 scale을 결정한다면 queue에 task가 많이 추가되는 시점에 더 빠르게 확장할 수 있습니다.
- 예를 들어 airflow는 metadb를 통해 현재 실행 중이거나 대기 중인 task가 얼마나 존재하는지 알 수 있습니다.
- 기존의 HPA(Horizontal Pod Autoscaler)는 리소스(CPU, Memory) 메트릭을 기반으로 스케일 여부를 결정하게 됩니다.
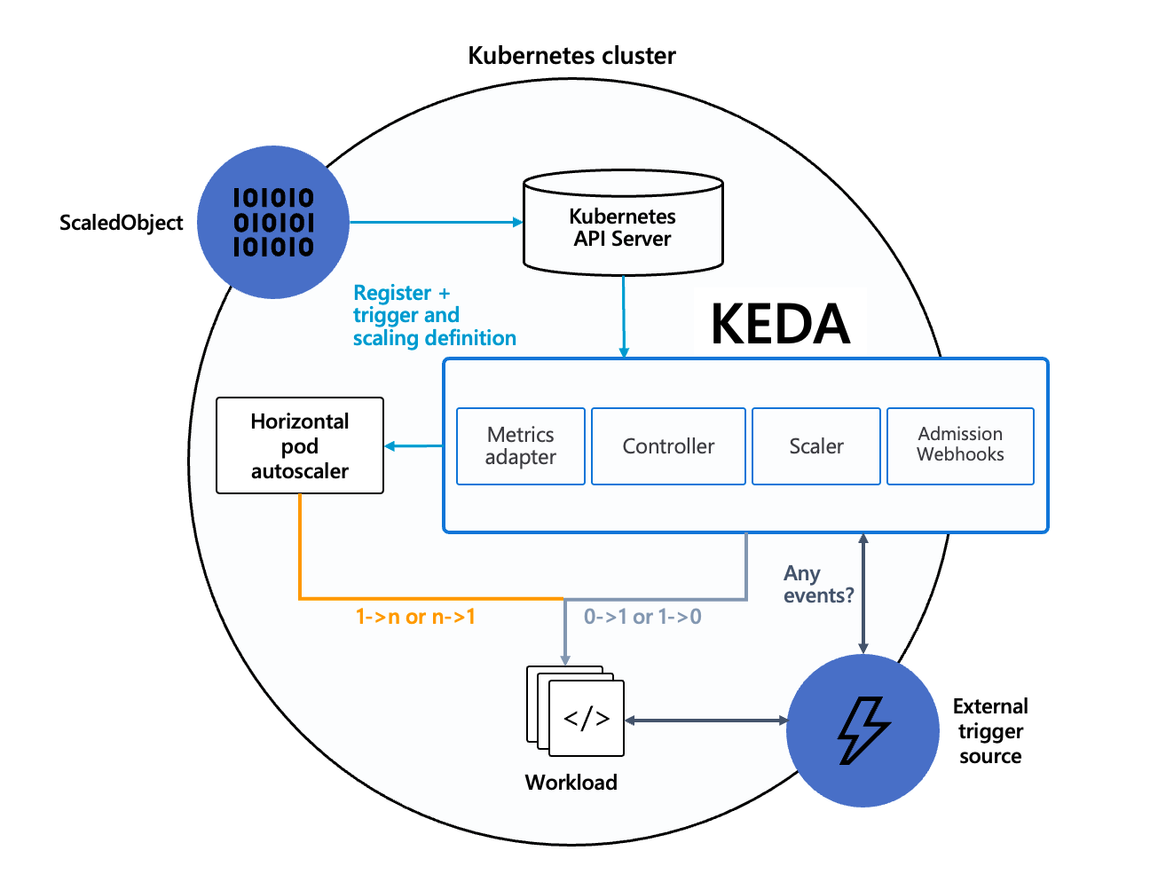
KEDA Scalers : kafka trigger for an Apache Kafka topic - 링크
KEDA | Apache Kafka
Scale applications based on an Apache Kafka topic or other services that support Kafka protocol.
keda.sh
triggers:
- type: kafka
metadata:
bootstrapServers: kafka.svc:9092 # Comma separated list of Kafka brokers “hostname:port” to connect to for bootstrap.
consumerGroup: my-group # Name of the consumer group used for checking the offset on the topic and processing the related lag.
topic: test-topic # Name of the topic on which processing the offset lag. (Optional, see note below)
lagThreshold: '5' # Average target value to trigger scaling actions. (Default: 5, Optional)
offsetResetPolicy: latest # The offset reset policy for the consumer. (Values: latest, earliest, Default: latest, Optional)
allowIdleConsumers: false # When set to true, the number of replicas can exceed the number of partitions on a topic, allowing for idle consumers. (Default: false, Optional)
scaleToZeroOnInvalidOffset: false
version: 1.0.0 # Version of your Kafka brokers. See samara version (Default: 1.0.0, Optional)
KEDA with Helm : 특정 이벤트(cron 등)기반의 파드 오토 스케일링 - Chart Grafana Cron SQS_Scale

# KEDA 설치
cat <<EOT > keda-values.yaml
metricsServer:
useHostNetwork: true
prometheus:
metricServer:
enabled: true
port: 9022
portName: metrics
path: /metrics
serviceMonitor:
# Enables ServiceMonitor creation for the Prometheus Operator
enabled: true
podMonitor:
# Enables PodMonitor creation for the Prometheus Operator
enabled: true
operator:
enabled: true
port: 8080
serviceMonitor:
# Enables ServiceMonitor creation for the Prometheus Operator
enabled: true
podMonitor:
# Enables PodMonitor creation for the Prometheus Operator
enabled: true
webhooks:
enabled: true
port: 8080
serviceMonitor:
# Enables ServiceMonitor creation for the Prometheus webhooks
enabled: true
EOT
kubectl create namespace keda
helm repo add kedacore https://kedacore.github.io/charts
helm install keda kedacore/keda --version 2.13.0 --namespace keda -f keda-values.yaml
# KEDA 설치 확인
kubectl get all -n keda
kubectl get validatingwebhookconfigurations keda-admission
kubectl get validatingwebhookconfigurations keda-admission | kubectl neat | yh
kubectl get crd | grep keda
# keda 네임스페이스에 디플로이먼트 생성
kubectl apply -f php-apache.yaml -n keda
kubectl get pod -n keda
# ScaledObject 정책 생성 : cron
cat <<EOT > keda-cron.yaml
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: php-apache-cron-scaled
spec:
minReplicaCount: 0
maxReplicaCount: 2
pollingInterval: 30
cooldownPeriod: 300
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: php-apache
triggers:
- type: cron
metadata:
timezone: Asia/Seoul
start: 00,15,30,45 * * * *
end: 05,20,35,50 * * * *
desiredReplicas: "1"
EOT
kubectl apply -f keda-cron.yaml -n keda
# 그라파나 대시보드 추가
# 모니터링
watch -d 'kubectl get ScaledObject,hpa,pod -n keda'
kubectl get ScaledObject -w
# 확인
kubectl get ScaledObject,hpa,pod -n keda
kubectl get hpa -o jsonpath={.items[0].spec} -n keda | jq
...
"metrics": [
{
"external": {
"metric": {
"name": "s0-cron-Asia-Seoul-00,15,30,45xxxx-05,20,35,50xxxx",
"selector": {
"matchLabels": {
"scaledobject.keda.sh/name": "php-apache-cron-scaled"
}
}
},
"target": {
"averageValue": "1",
"type": "AverageValue"
}
},
"type": "External"
}
# KEDA 및 deployment 등 삭제
kubectl delete -f keda-cron.yaml -n keda && kubectl delete deploy php-apache -n keda && helm uninstall keda -n keda
kubectl delete namespace keda
확인
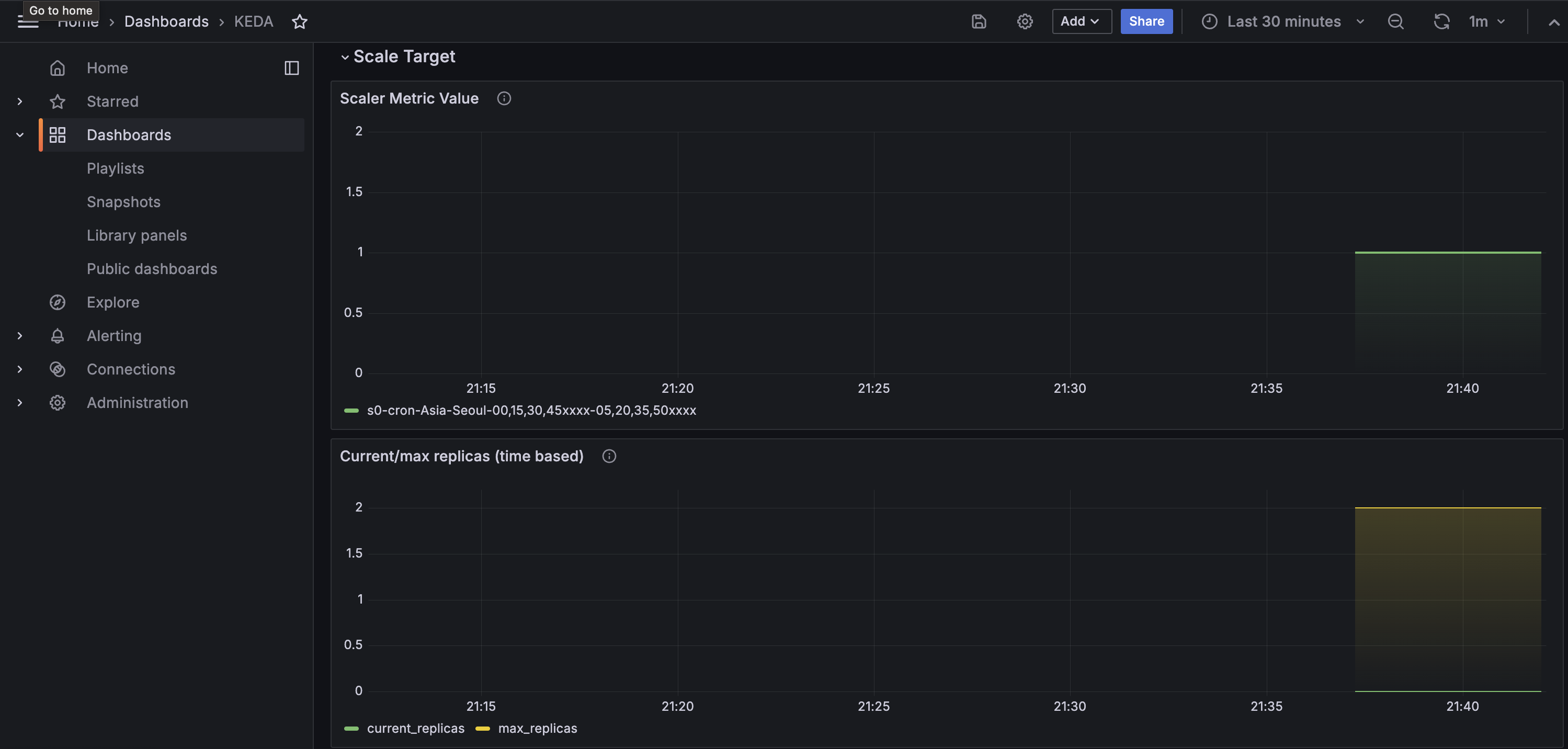
3. VPA - Vertical Pod Autoscaler
VPA - 링크 : pod resources.request을 최대한 최적값으로 수정, HPA와 같이 사용 불가능, 수정 시 파드 재실행 ← 악분님 포스팅 내용
# 코드 다운로드
git clone https://github.com/kubernetes/autoscaler.git
cd ~/autoscaler/vertical-pod-autoscaler/
tree hack
# openssl 버전 확인
openssl version
OpenSSL 1.0.2k-fips 26 Jan 2017
# openssl 1.1.1 이상 버전 확인
yum install openssl11 -y
openssl11 version
OpenSSL 1.1.1g FIPS 21 Apr 2020
# 스크립트파일내에 openssl11 수정
sed -i 's/openssl/openssl11/g' ~/autoscaler/vertical-pod-autoscaler/pkg/admission-controller/gencerts.sh
# Deploy the Vertical Pod Autoscaler to your cluster with the following command.
watch -d kubectl get pod -n kube-system
cat hack/vpa-up.sh
./hack/vpa-up.sh
kubectl get crd | grep autoscaling
kubectl get mutatingwebhookconfigurations vpa-webhook-config
kubectl get mutatingwebhookconfigurations vpa-webhook-config -o json | jq
- 공식 예제 : pod가 실행되면 약 2~3분 뒤에 pod resource.reqeust가 VPA에 의해 수정 - 링크
- vpa에 spec.updatePolicy.updateMode를 Off 로 변경 시 파드에 Spec을 자동으로 변경 재실행 하지 않습니다. 기본값(Auto)
# 모니터링
watch -d "kubectl top pod;echo "----------------------";kubectl describe pod | grep Requests: -A2"
# 공식 예제 배포
cd ~/autoscaler/vertical-pod-autoscaler/
cat examples/hamster.yaml | yh
kubectl apply -f examples/hamster.yaml && kubectl get vpa -w
# 파드 리소스 Requestes 확인
kubectl describe pod | grep Requests: -A2
Requests:
cpu: 100m
memory: 50Mi
--
Requests:
cpu: 587m
memory: 262144k
--
Requests:
cpu: 587m
memory: 262144k
# VPA에 의해 기존 파드 삭제되고 신규 파드가 생성됨
kubectl get events --sort-by=".metadata.creationTimestamp" | grep VPA
2m16s Normal EvictedByVPA pod/hamster-5bccbb88c6-s6jkp Pod was evicted by VPA Updater to apply resource recommendation.
76s Normal EvictedByVPA pod/hamster-5bccbb88c6-jc6gq Pod was evicted by VPA Updater to apply resource recommendation.
확인
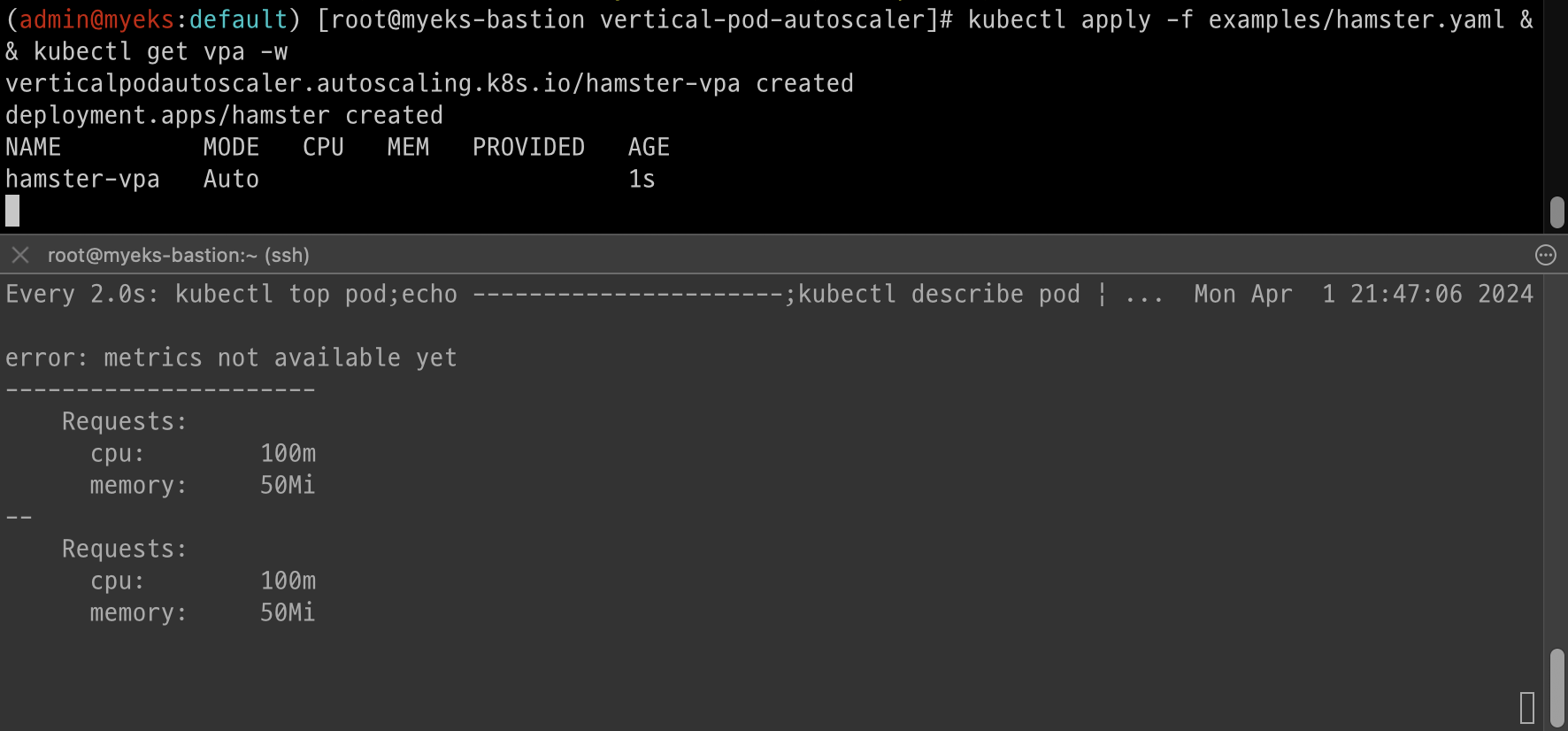
그라파나 확인
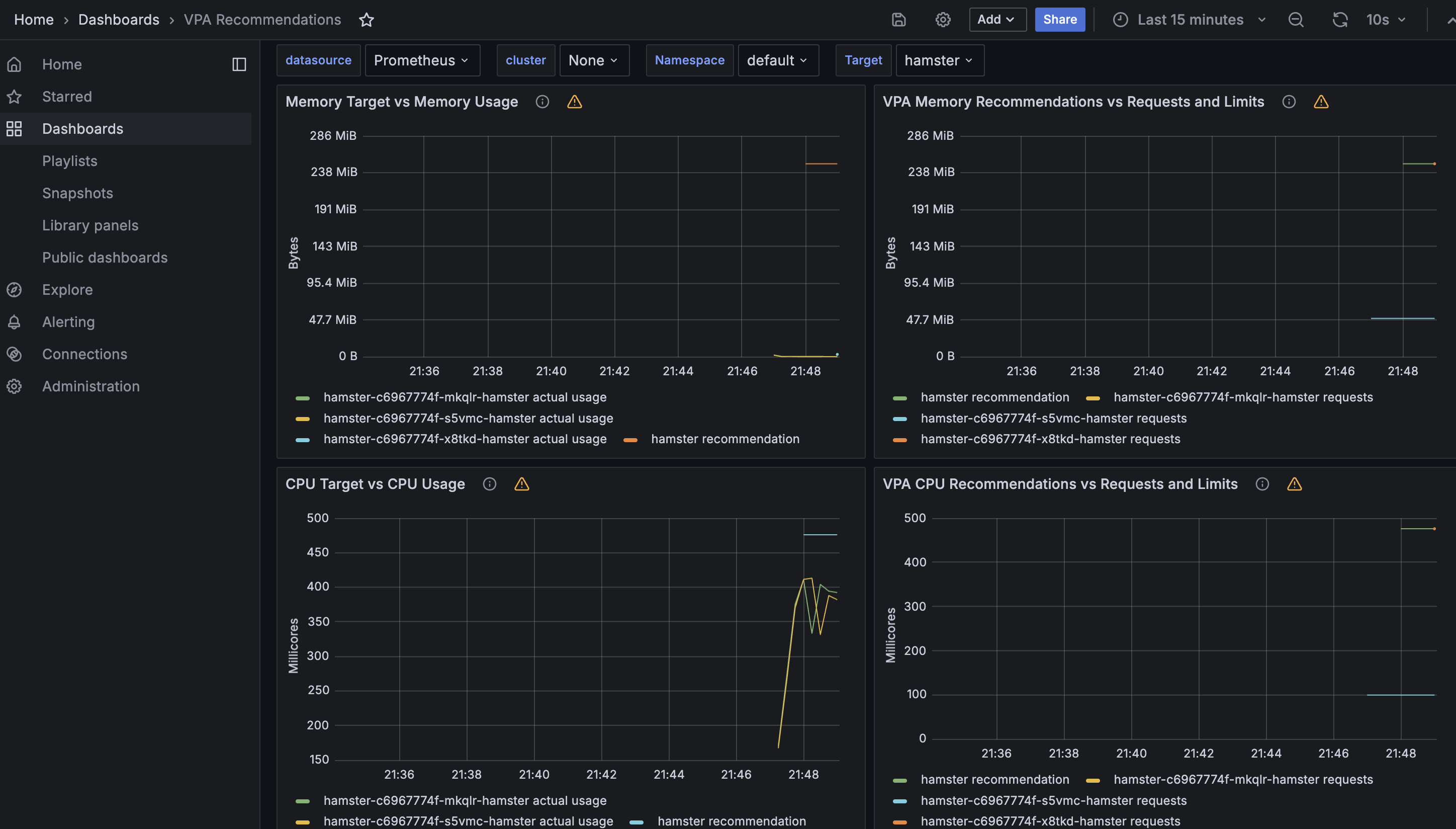
삭제: kubectl delete -f examples/hamster.yaml && cd ~/autoscaler/vertical-pod-autoscaler/ && ./hack/vpa-down.sh
4. CA - Cluster Autoscaler

- Cluster Autoscale 동작을 하기 위한 cluster-autoscaler 파드(디플로이먼트)를 배치합니다.
- **Cluster Autoscaler(CA)**는 pending 상태인 파드가 존재할 경우, 워커 노드를 스케일 아웃합니다.
- 특정 시간을 간격으로 사용률을 확인하여 스케일 인/아웃을 수행합니다. 그리고 AWS에서는 Auto Scaling Group(ASG)을 사용하여 Cluster Autoscaler를 적용합니다.
Cluster Autoscaler(CA) 설정 - 링크 Helm
설정 전 확인
# EKS 노드에 이미 아래 tag가 들어가 있음
# k8s.io/cluster-autoscaler/enabled : true
# k8s.io/cluster-autoscaler/myeks : owned
aws ec2 describe-instances --filters Name=tag:Name,Values=$CLUSTER_NAME-ng1-Node --query "Reservations[*].Instances[*].Tags[*]" --output yaml | yh
...
- Key: k8s.io/cluster-autoscaler/myeks
Value: owned
- Key: k8s.io/cluster-autoscaler/enabled
Value: 'true'
...
# 현재 autoscaling(ASG) 정보 확인
# aws autoscaling describe-auto-scaling-groups --query "AutoScalingGroups[? Tags[? (Key=='eks:cluster-name') && Value=='클러스터이름']].[AutoScalingGroupName, MinSize, MaxSize,DesiredCapacity]" --output table
aws autoscaling describe-auto-scaling-groups \
--query "AutoScalingGroups[? Tags[? (Key=='eks:cluster-name') && Value=='myeks']].[AutoScalingGroupName, MinSize, MaxSize,DesiredCapacity]" \
--output table
-----------------------------------------------------------------
| DescribeAutoScalingGroups |
+------------------------------------------------+----+----+----+
| eks-ng1-44c41109-daa3-134c-df0e-0f28c823cb47 | 3 | 3 | 3 |
+------------------------------------------------+----+----+----+
# MaxSize 6개로 수정
export ASG_NAME=$(aws autoscaling describe-auto-scaling-groups --query "AutoScalingGroups[? Tags[? (Key=='eks:cluster-name') && Value=='myeks']].AutoScalingGroupName" --output text)
aws autoscaling update-auto-scaling-group --auto-scaling-group-name ${ASG_NAME} --min-size 3 --desired-capacity 3 --max-size 6
# 확인
aws autoscaling describe-auto-scaling-groups --query "AutoScalingGroups[? Tags[? (Key=='eks:cluster-name') && Value=='myeks']].[AutoScalingGroupName, MinSize, MaxSize,DesiredCapacity]" --output table
-----------------------------------------------------------------
| DescribeAutoScalingGroups |
+------------------------------------------------+----+----+----+
| eks-ng1-c2c41e26-6213-a429-9a58-02374389d5c3 | 3 | 6 | 3 |
+------------------------------------------------+----+----+----+
# 배포 : Deploy the Cluster Autoscaler (CA)
curl -s -O https://raw.githubusercontent.com/kubernetes/autoscaler/master/cluster-autoscaler/cloudprovider/aws/examples/cluster-autoscaler-autodiscover.yaml
sed -i "s/<YOUR CLUSTER NAME>/$CLUSTER_NAME/g" cluster-autoscaler-autodiscover.yaml
kubectl apply -f cluster-autoscaler-autodiscover.yaml
# 확인
kubectl get pod -n kube-system | grep cluster-autoscaler
kubectl describe deployments.apps -n kube-system cluster-autoscaler
kubectl describe deployments.apps -n kube-system cluster-autoscaler | grep node-group-auto-discovery
--node-group-auto-discovery=asg:tag=k8s.io/cluster-autoscaler/enabled,k8s.io/cluster-autoscaler/myeks
# (옵션) cluster-autoscaler 파드가 동작하는 워커 노드가 퇴출(evict) 되지 않게 설정
kubectl -n kube-system annotate deployment.apps/cluster-autoscaler cluster-autoscaler.kubernetes.io/safe-to-evict="false"
오토스케일링 늘려보기

SCALE A CLUSTER WITH Cluster Autoscaler(CA) - 링크
# 모니터링
kubectl get nodes -w
while true; do kubectl get node; echo "------------------------------" ; date ; sleep 1; done
while true; do aws ec2 describe-instances --query "Reservations[*].Instances[*].{PrivateIPAdd:PrivateIpAddress,InstanceName:Tags[?Key=='Name']|[0].Value,Status:State.Name}" --filters Name=instance-state-name,Values=running --output text ; echo "------------------------------"; date; sleep 1; done
# Deploy a Sample App
# We will deploy an sample nginx application as a ReplicaSet of 1 Pod
cat <<EoF> nginx.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-to-scaleout
spec:
replicas: 1
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
service: nginx
app: nginx
spec:
containers:
- image: nginx
name: nginx-to-scaleout
resources:
limits:
cpu: 500m
memory: 512Mi
requests:
cpu: 500m
memory: 512Mi
EoF
kubectl apply -f nginx.yaml
kubectl get deployment/nginx-to-scaleout
# Scale our ReplicaSet
# Let’s scale out the replicaset to 15
kubectl scale --replicas=15 deployment/nginx-to-scaleout && date
# 확인
kubectl get pods -l app=nginx -o wide --watch
kubectl -n kube-system logs -f deployment/cluster-autoscaler
# 노드 자동 증가 확인
kubectl get nodes
aws autoscaling describe-auto-scaling-groups \
--query "AutoScalingGroups[? Tags[? (Key=='eks:cluster-name') && Value=='myeks']].[AutoScalingGroupName, MinSize, MaxSize,DesiredCapacity]" \
--output table
./eks-node-viewer --resources cpu,memory
혹은
./eks-node-viewer
# 디플로이먼트 삭제
kubectl delete -f nginx.yaml && date
# 노드 갯수 축소 : 기본은 10분 후 scale down 됨, 물론 아래 flag 로 시간 수정 가능 >> 그러니 디플로이먼트 삭제 후 10분 기다리고 나서 보자!
# By default, cluster autoscaler will wait 10 minutes between scale down operations,
# you can adjust this using the --scale-down-delay-after-add, --scale-down-delay-after-delete,
# and --scale-down-delay-after-failure flag.
# E.g. --scale-down-delay-after-add=5m to decrease the scale down delay to 5 minutes after a node has been added.
# 터미널1
watch -d kubectl get node
확인해보면 파드가 pending상태
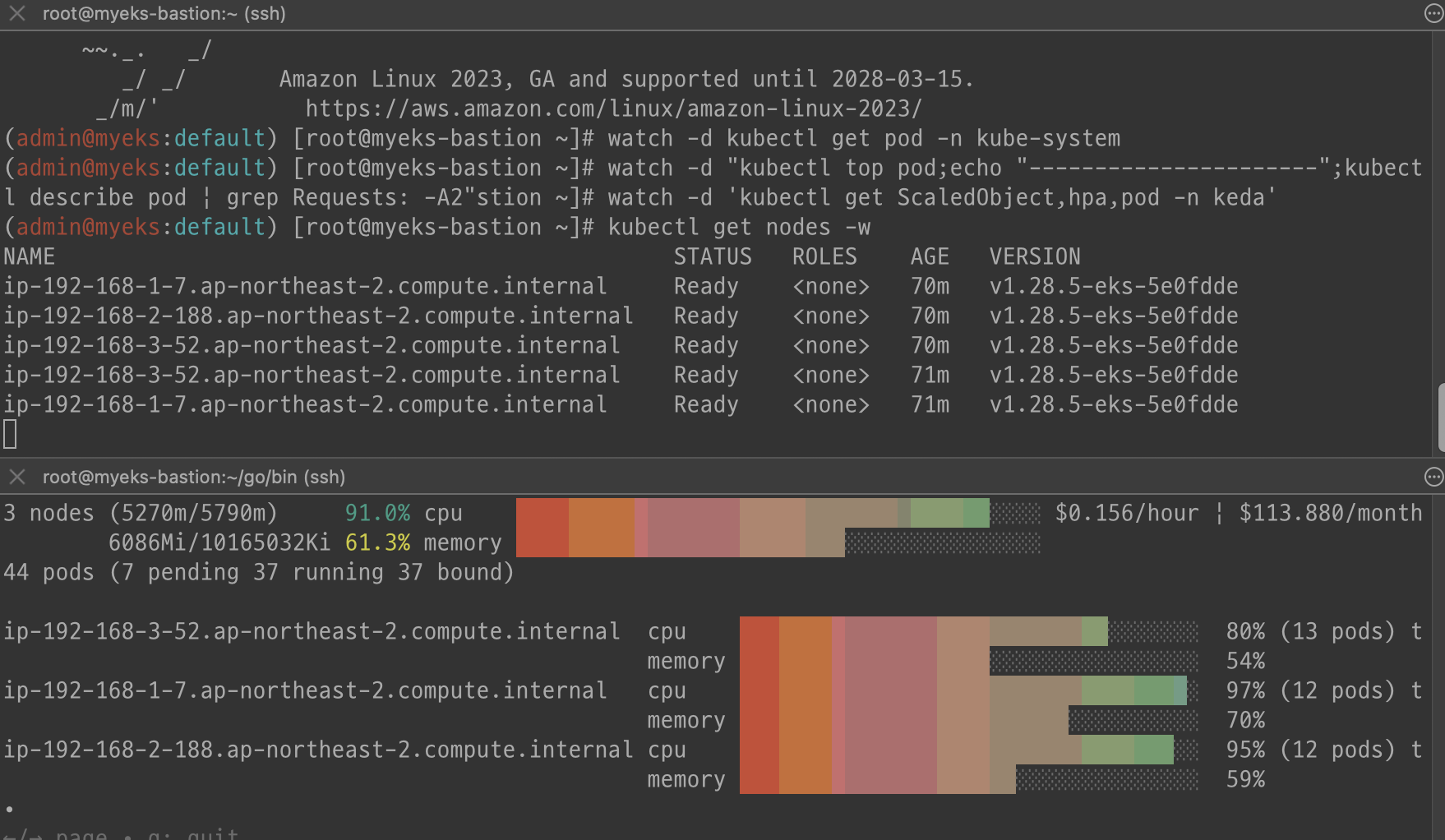
노드가 추가적으로 생성
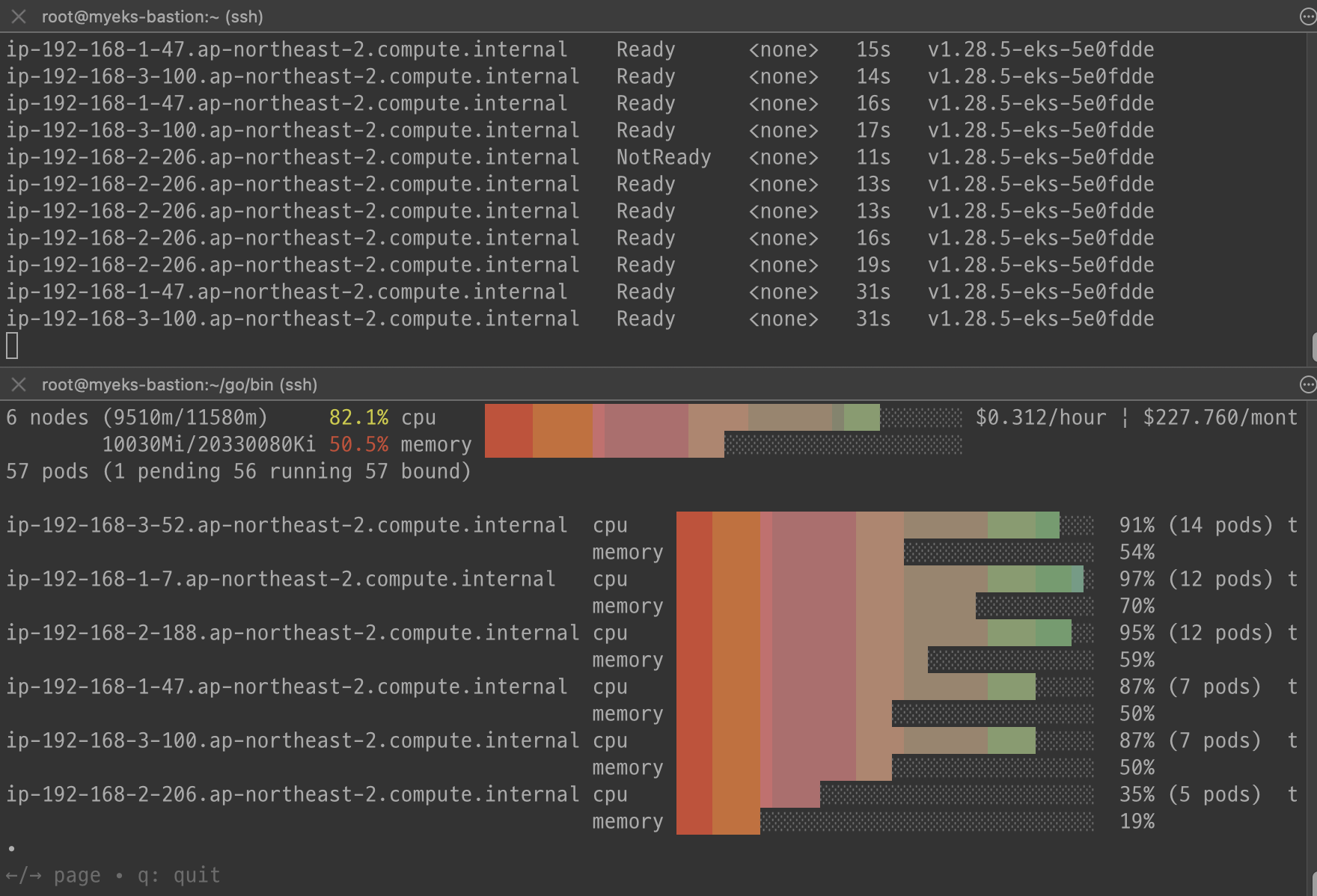
리소스 삭제
위 실습 중 디플로이먼트 삭제 후 10분 후 노드 갯수 축소되는 것을 확인 후 아래 삭제를 해보자! >> 만약 바로 아래 CA 삭제 시 워커 노드는 4개 상태가 되어서 수동으로 2대 변경 하자!
kubectl delete -f nginx.yaml
# size 수정
aws autoscaling update-auto-scaling-group --auto-scaling-group-name ${ASG_NAME} --min-size 3 --desired-capacity 3 --max-size 3
aws autoscaling describe-auto-scaling-groups --query "AutoScalingGroups[? Tags[? (Key=='eks:cluster-name') && Value=='myeks']].[AutoScalingGroupName, MinSize, MaxSize,DesiredCapacity]" --output table
# Cluster Autoscaler 삭제
kubectl delete -f cluster-autoscaler-autodiscover.yaml
- CA 문제점 : 하나의 자원에 대해 두군데 (AWS ASG vs AWS EKS)에서 각자의 방식으로 관리 ⇒ 관리 정보가 서로 동기화되지 않아 다양한 문제 발생
- CA 문제점 : ASG에만 의존하고 노드 생성/삭제 등에 직접 관여 안함
- EKS에서 노드를 삭제 해도 인스턴스는 삭제 안됨
- 노드 축소 될 때 특정 노드가 축소 되도록 하기 매우 어려움 : pod이 적은 노드 먼저 축소, 이미 드레인 된 노드 먼저 축소
- 특정 노드를 삭제 하면서 동시에 노드 개수를 줄이기 어려움 : 줄일때 삭제 정책 옵션이 다양하지 않음
- 정책 미지원 시 삭제 방식(예시) : 100대 중 미삭제 EC2 보호 설정 후 삭제 될 ec2의 파드를 이주 후 scaling 조절로 삭제 후 원복
- 특정 노드를 삭제하면서 동시에 노드 개수를 줄이기 어려움
- 폴링 방식이기에 너무 자주 확장 여유를 확인 하면 API 제한에 도달할 수 있음
- 스케일링 속도가 매우 느림
- Cluster Autoscaler 는 쿠버네티스 클러스터 자체의 오토 스케일링을 의미하며, 수요에 따라 워커 노드를 자동으로 추가하는 기능
- 언뜻 보기에 클러스터 전체나 각 노드의 부하 평균이 높아졌을 때 확장으로 보인다 → 함정! 🚧
- Pending 상태의 파드가 생기는 타이밍에 처음으로 Cluster Autoscaler 이 동작한다
- 즉, Request 와 Limits 를 적절하게 설정하지 않은 상태에서는 실제 노드의 부하 평균이 낮은 상황에서도 스케일 아웃이 되거나, 부하 평균이 높은 상황임에도 스케일 아웃이 되지 않는다!
- 기본적으로 리소스에 의한 스케줄링은 Requests(최소)를 기준으로 이루어진다. 다시 말해 Requests 를 초과하여 할당한 경우에는 최소 리소스 요청만으로 리소스가 꽉 차 버려서 신규 노드를 추가해야만 한다. 이때 실제 컨테이너 프로세스가 사용하는 리소스 사용량은 고려되지 않는다.
- 반대로 Request 를 낮게 설정한 상태에서 Limit 차이가 나는 상황을 생각해보자. 각 컨테이너는 Limits 로 할당된 리소스를 최대로 사용한다. 그래서 실제 리소스 사용량이 높아졌더라도 Requests 합계로 보면 아직 스케줄링이 가능하기 때문에 클러스터가 스케일 아웃하지 않는 상황이 발생한다.
- 여기서는 CPU 리소스 할당을 예로 설명했지만 메모리의 경우도 마찬가지다.
5. CPA - Cluster Proportional Autoscaler
노드 수 증가에 비례하여 성능 처리가 필요한 애플리케이션(컨테이너/파드)를 수평으로 자동 확장 ex. coredns - Github Workshop
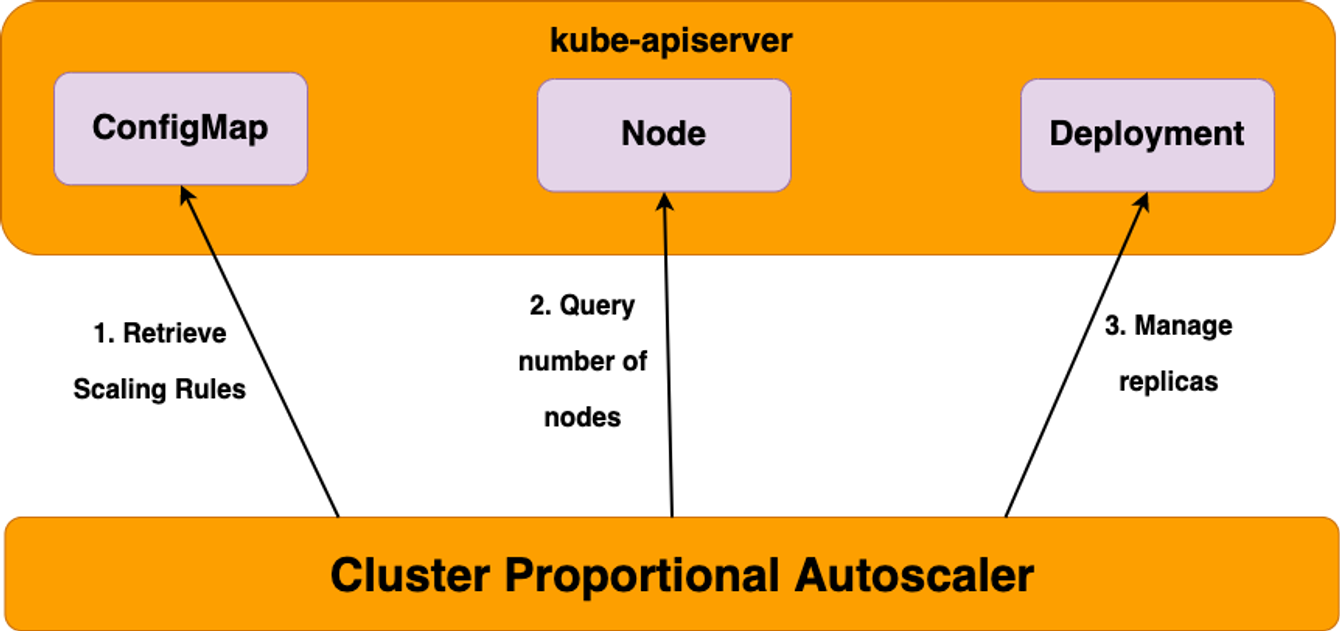
#
helm repo add cluster-proportional-autoscaler https://kubernetes-sigs.github.io/cluster-proportional-autoscaler
# CPA규칙을 설정하고 helm차트를 릴리즈 필요
helm upgrade --install cluster-proportional-autoscaler cluster-proportional-autoscaler/cluster-proportional-autoscaler
# nginx 디플로이먼트 배포
cat <<EOT > cpa-nginx.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
spec:
replicas: 1
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:latest
resources:
limits:
cpu: "100m"
memory: "64Mi"
requests:
cpu: "100m"
memory: "64Mi"
ports:
- containerPort: 80
EOT
kubectl apply -f cpa-nginx.yaml
# CPA 규칙 설정
cat <<EOF > cpa-values.yaml
config:
ladder:
nodesToReplicas:
- [1, 1]
- [2, 2]
- [3, 3]
- [4, 3]
- [5, 5]
options:
namespace: default
target: "deployment/nginx-deployment"
EOF
kubectl describe cm cluster-proportional-autoscaler
# 모니터링
watch -d kubectl get pod
# helm 업그레이드
helm upgrade --install cluster-proportional-autoscaler -f cpa-values.yaml cluster-proportional-autoscaler/cluster-proportional-autoscaler
# 노드 5개로 증가
export ASG_NAME=$(aws autoscaling describe-auto-scaling-groups --query "AutoScalingGroups[? Tags[? (Key=='eks:cluster-name') && Value=='myeks']].AutoScalingGroupName" --output text)
aws autoscaling update-auto-scaling-group --auto-scaling-group-name ${ASG_NAME} --min-size 5 --desired-capacity 5 --max-size 5
aws autoscaling describe-auto-scaling-groups --query "AutoScalingGroups[? Tags[? (Key=='eks:cluster-name') && Value=='myeks']].[AutoScalingGroupName, MinSize, MaxSize,DesiredCapacity]" --output table
# 노드 4개로 축소
aws autoscaling update-auto-scaling-group --auto-scaling-group-name ${ASG_NAME} --min-size 4 --desired-capacity 4 --max-size 4
aws autoscaling describe-auto-scaling-groups --query "AutoScalingGroups[? Tags[? (Key=='eks:cluster-name') && Value=='myeks']].[AutoScalingGroupName, MinSize, MaxSize,DesiredCapacity]" --output table
노드의 개수에 비례해서 파드가 배포 된다.
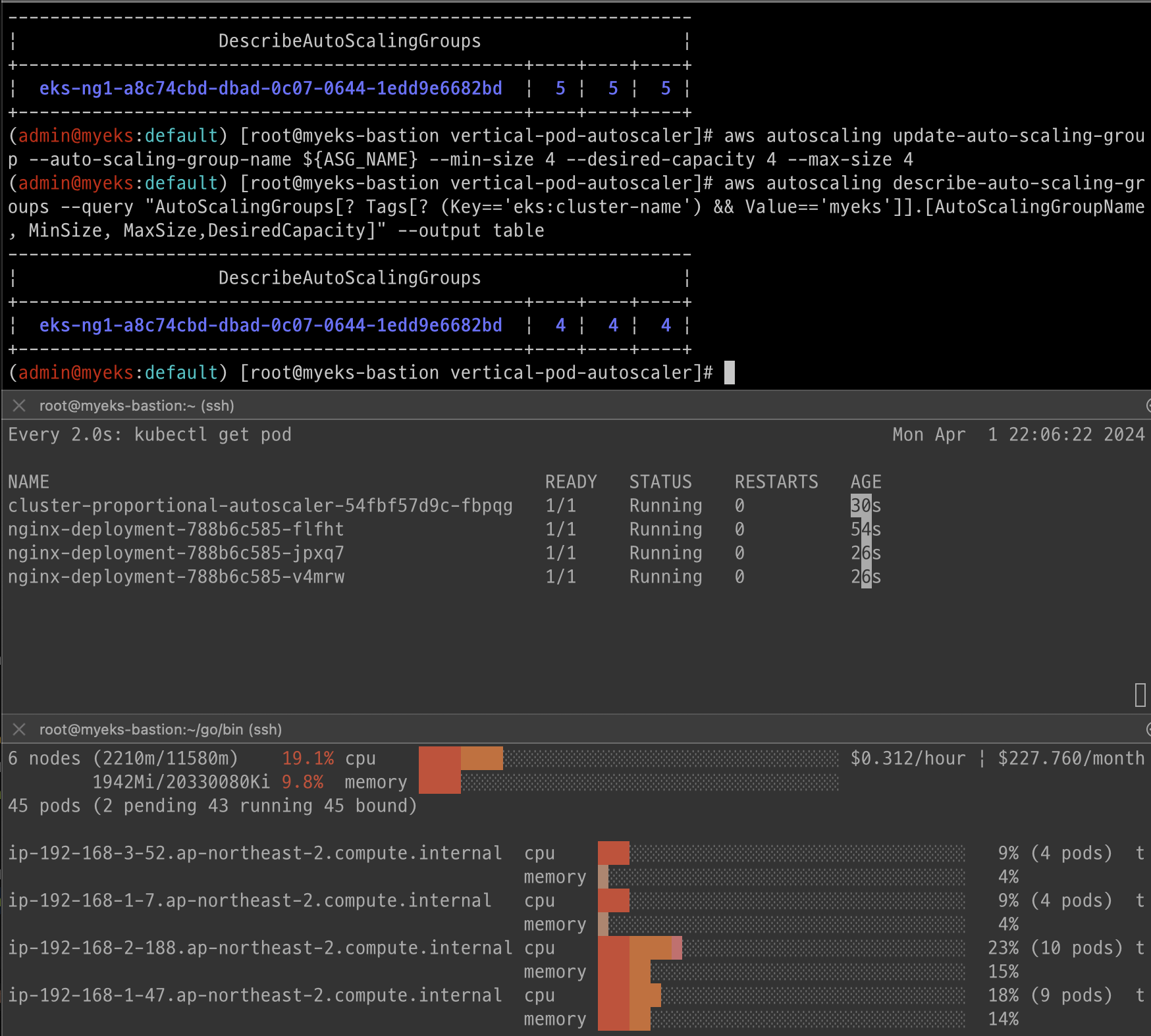
삭제: helm uninstall cluster-proportional-autoscaler && kubectl delete -f cpa-nginx.yaml
'study > AEWS 2기' 카테고리의 다른 글
| AEWS 2기 6주차 첫번째 (1) | 2024.04.10 |
|---|---|
| AEWS 2기 5주차 두번째 (4) | 2024.04.05 |
| AEWS 2기 4주차 세번째 (1) | 2024.03.30 |
| AEWS 2기 4주차 두번째 (1) | 2024.03.30 |
| AEWS 2기 4주차 첫번째 (0) | 2024.03.25 |



